Fix for 3-billion-year-old genetic error could dramatically improve genetic sequencing

For 3 billion years, one of the major carriers of information needed for life, RNA, has had a glitch that creates errors when making copies of genetic information. Researchers at The University of Texas at Austin have developed a fix that allows RNA to accurately proofread for the first time. The new discovery, published June 23 in the journal Science, will increase precision in genetic research and could dramatically improve medicine based on a person's genetic makeup.
Certain viruses called retroviruses can cause RNA to make copies of DNA, a process called reverse transcription. This process is notoriously prone to errors because an evolutionary ancestor of all viruses never had the ability to accurately copy genetic material.
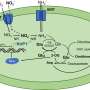
The new innovation engineered at UT Austin is an enzyme that performs reverse transcription but can also "proofread," or check its work while copying genetic code. The enzyme allows, for the first time, for large amounts of RNA information to be copied with near perfect accuracy.
"We created a new group of enzymes that can read the genetic information inside living cells with unprecedented accuracy," says Jared Ellefson, a postdoctoral fellow in UT Austin's Center for Systems and Synthetic Biology. "Overlooked by evolution, our enzyme can correct errors while copying RNA."
Reverse transcription is mainly associated with retroviruses such as HIV. In nature, these viruses' inability to copy DNA accurately may have helped create variety in species over time, contributing to the complexity of life as we know it.
Since discovering reverse transcription, scientists have used it to better understand genetic information related to inheritable diseases and other aspects of human health. Still, the error-prone nature of existing RNA sequencing is a problem for scientists.
"With proofreading, our new enzyme increases precision and fidelity of RNA sequencing," says Ellefson. "Without the ability to faithfully read RNA, we cannot accurately determine the inner workings of cells. These errors can lead to misleading data in the research lab and potential misdiagnosis in the clinical lab."
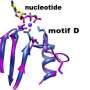
Ellefson and the team of researchers engineered the new enzyme using directed evolution to train a high-fidelity (proofreading) DNA polymerase to use RNA templates. The new enzyme, called RTX, retains the highly accurate and efficient proofreading function, while copying RNA. Accuracy is improved at least threefold, and it may be up to 10 times as accurate. This new enzyme could enhance the methods used to read RNA from cells.
"As we move towards an age of personalized medicine where everyone's transcripts will be read out almost as easily as taking a pulse, the accuracy of the sequence information will become increasingly important," said Andy Ellington, a professor of molecular biosciences. "The significance of this is that we can now also copy large amounts of RNA information found in modern genomes, in the form of the RNA transcripts that encode almost every aspect of our physiology. This means that diagnoses made based on genomic information are far more likely to be accurate. "
More information: "Synthetic evolutionary origin of a proofreading reverse transcriptase," Science, DOI: 10.1126/science.aaf5409
Journal information: Science
Provided by University of Texas at Austin