Team develops vision system that improves object recognition
A research group at Disney Research Pittsburgh has developed a computer vision system that, much like humans, can continuously improve its ability to recognize objects by picking up hints while watching videos.
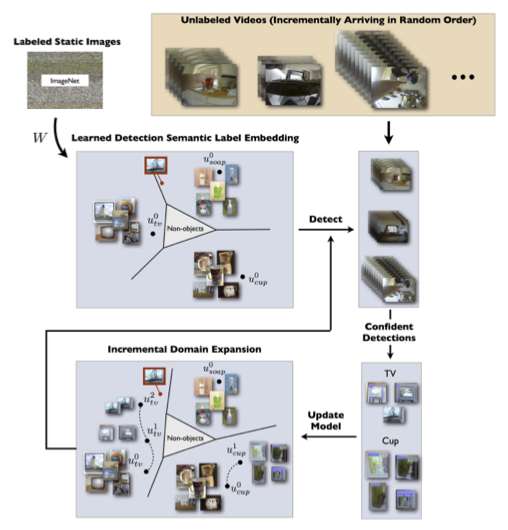
Like most other object recognition systems, the Disney system builds a conceptual model of an object, be it an airplane or a soap dispenser, by using a learning algorithm to analyze a number of example images of the object.
What's different about the Disney system is that it then uses that model to identify objects, when it can, in videos. As it does, it sometimes is able to glean new information about such objects, enabling it to make its own model of the object more complex. And that in turn enables the system to more readily recognize such objects in a wider variety of conditions.
"This process continues, potentially indefinitely, over the lifetime of the recognition system," said Leonid Sigal, a senior research scientist at Disney Research Pittsburgh. "This is a learning system that is continuously evolving through unsupervised experience to build a more complete and complex model of the world."
Sigal and his co-investigators - Alina Kuznetsova and Bodo Rosenhahn of Leibniz University Hannover, and former Disney post-doctoral researcher Sung Ju Hwang, now of Ulsan National Institute of Science and Technology in South Korea - will present their findings at the IEEE Conference on Computer Vision and Pattern Recognition, CVPR 2015, June 7-12, in Boston.
Recognizing objects in images, though often easy for humans, remains a challenge for automated systems. Systems that learn to recognize objects using one set of images may have difficulty recognizing those same objects in the real world, or under different sets of conditions, or domains.
Rather than try to get a system to more accurately recognize objects using its original model for that object in new domains, the Disney group took a different approach - expanding the object domain incrementally. That means that the system's model for each object will be continuously fine-tuned as the system encounters new information.
One potential problem is that the system, which does this fine tuning without human supervision, may start ascribing attributes to an object that aren't pertinent and lead to errors in detection, but thus far this "domain drift" has not been detected by the Disney researchers.
They tested their incremental learning method against several other leading object recognition methods, using two standard video datasets that included a variety of objects found in the home. In most instances, it outperformed the other methods in detecting items such as microwave ovens, mugs and stoves and demonstrated that it not only got better with experience at detecting these objects in the videos, but also in detecting objects from its original training images.
More information: "Expanding Object Detector's HORIZON-Paper" www.disneyresearch.com/wp-cont … ding-Object-Detector%E2%80%99s-HORIZON-Incremental-Learning-Framework-for-Object-Detection-in-Videos-Paper.pdf
Provided by Disney Research